Manually labeling data for machine learning is a notoriously laborious process. It’s slow, repetitive, costly, and frequently becomes the major bottleneck hindering AI and Machine Learning (ML) teams 1. To overcome this hurdle, AI developers have long sought ways to automate data labeling, aiming for what is often called “automated data labeling” [2](#footnotes]. Traditional methods like active learning and model-assisted labeling have been explored, but their impact on truly accelerating AI development has been limited.
For over half a decade, the Snorkel team, originating from the Stanford AI Lab and now at Snorkel AI, has been deeply invested in solving this challenge. Through workshops [3](#footnotes], collaborations with academic, industry, and government partners [4](#footnotes], and over 55 published research papers [5](#footnotes], they have rigorously examined various automation techniques. Their extensive experience using different methods, including those mentioned above, has revealed that these partial automations of manual labeling simply don’t deliver the substantial speed increase needed for practical, modern AI development. This realization propelled them to pioneer programmatic labeling, a revolutionary approach that transforms automated data labeling from a concept into a tangible reality.
This article will compare and contrast manual labeling optimization techniques with programmatic labeling. Here’s a summary of the key distinctions:
- Manual labeling enhancements like active learning and model-assisted pre-labeling offer incremental speed improvements for labeling individual data points. While valuable and established techniques, they inherit the fundamental limitations of manual annotation, such as lack of scalability, adaptability, and governability.
- Programmatic labeling, conversely, unlocks a significantly more scalable method for automating data labeling. It achieves 10-100x acceleration—a dramatic leap from the marginal 10% improvements seen with manual optimizations—by leveraging a fundamentally more efficient and reusable form of user input: labeling functions. This empowers teams to label significantly larger datasets, adapt to evolving requirements, and effectively inspect and rectify biases within the labeling process.
- Snorkel Flow stands out as a data-centric platform designed for building AI applications, seamlessly integrating programmatic labeling, active learning, and numerous other cutting-edge ML techniques. The compatibility of these techniques within Snorkel Flow empowers data scientists and subject matter experts to harness every possible advantage of automated data labeling, both large and small.
Manual vs. Programmatic Input: A Fundamental Shift in Auto Data Labeling
The core distinction between manual labeling (optimized or not) and programmatic labeling lies in the type of input provided by the user. Manual labeling relies on users providing individual labels, one by one. Programmatic labeling, a form of weak supervision explained in detail later, instead involves users creating labeling functions. These functions capture the rationale behind labeling decisions and can be automatically applied to vast quantities of unlabeled data to generate individual labels. This difference in input type has profound implications for the scalability, adaptability, and governance of the entire Auto Data Labeling workflow.
Scalability: Amplifying Expertise in Auto Data Labeling
Programmatic labeling dramatically improves scalability by enabling direct and efficient knowledge transfer.
Manual data labeling can be likened to playing a never-ending game of twenty questions [6](#footnotes]. Experts are tasked with labeling data using their internal knowledge and heuristics. Subsequently, significant time, resources, and effort are spent having an ML model statistically re-learn the very knowledge the experts already possessed!
A key advantage of using labeling functions to transfer knowledge is the direct incorporation of expert insights. This results in a far more efficient knowledge transfer process. In many instances, it leads to savings of orders of magnitude in both time and cost [7](#footnotes], empowering domain experts to directly influence model behavior.
Adaptability: Agile Auto Data Labeling for Evolving Needs
Programmatic labeling ensures adaptable training labels that can be easily updated and reproduced.
When project requirements change, data drifts, or new error patterns emerge, training datasets require relabeling. With manual labeling, this means revisiting and re-labeling each affected data point—potentially multiple times. This significantly multiplies the time and financial costs of maintaining a high-quality, evolving model.
In contrast, when labels are generated programmatically, recreating the entire training dataset is as simple as modifying or adding a small number of targeted labeling functions and re-executing them. This relabeling process can then be performed at computer speed, not human speed, allowing for rapid adaptation to change.
Governability: Transparent and Correctable Auto Data Labeling
Programmatic labeling enhances governance by making the training set generation process inspectable and correctable.
Traditional manual labeling workflows often lack a record of the labeler’s thought process behind each label. This opacity makes auditing labeling decisions—both in general and for specific examples—challenging. This poses significant obstacles for compliance, safety, and quality control.
Programmatic labeling provides full traceability; every training label can be traced back to specific, inspectable labeling functions. If bias or undesirable model behavior is detected, the source can be traced back to the relevant labeling functions. These functions can then be refined or removed, and the training dataset can be programmatically regenerated within minutes, ensuring a more governable and trustworthy AI development process.
Automating Auto Data Labeling at the Optimal Level
While the goal of automated data labeling—to eliminate the slow, tedious, and expensive aspects—is clear, the extent and nature of automation are nuanced. Various techniques have been developed to make providing individual labels slightly more efficient or user-friendly (improved interfaces, model-assisted pre-labeling, active learning, etc.). However, the fundamental limitations persist because the core input remains unchanged: individual labels, collected one at a time, without explicit rationale.
Conversely, attempting to automate too much can also be problematic. The notion of fully automating training data labeling into a push-button process devoid of human input—essentially creating something from nothing—is akin to pursuing a modern-day perpetual motion machine [20](#footnotes]: ultimately futile. Human expertise remains indispensable; it provides the domain knowledge that models require.
The key to effective automated data labeling lies in raising the level of abstraction at which data scientists and domain experts interact with the data. The human element isn’t removed from the loop entirely, nor is it kept at the center of the labeling bottleneck. Instead, human expertise is elevated—domain knowledge is transferred through higher-level, scalable inputs—labeling functions that capture the reasoning behind labeling decisions—rather than individual labels.
With this crucial distinction in mind, let’s examine manual labeling techniques in greater detail.
Optimizing Manual Data Labeling Workflows
Manual Data Labeling: The Baseline
Let’s begin by considering vanilla manual labeling, without any automation.
Many significant AI achievements have been built upon manually labeled datasets. However, some of these datasets have required person-years to compile (consider ImageNet 8. The vast majority of machine learning projects simply lack the time or budget for such extensive manual effort.
Beyond being slow and expensive, manual labeling scales poorly. Except for minor efficiency gains from increased familiarity with the dataset and annotation guidelines, label collection rate remains roughly proportional to the human effort invested. In other words, your millionth label costs approximately the same as your hundredth. Furthermore, any significant changes to input data or output objectives—such as revised annotation instructions, data distribution shifts, or evolving model requirements—typically necessitate complete dataset relabeling from scratch, incurring costs equivalent to the initial effort [9](#footnotes].
Privacy concerns and the need for subject matter expertise often restrict the pool of qualified labelers. While some manual labeling tasks are simple enough for crowdsourcing, most enterprise-level tasks require domain-specific knowledge. Additionally, organizations are often hesitant to expose sensitive internal data to external parties. Consequently, the number of individuals qualified to label data for critical tasks can be extremely limited, further exacerbating the bottleneck.
Improved labeling UIs can offer marginal relief. Streamlined project setup, keyboard shortcuts, auto-advancing features, and point-and-click options (like those in the Snorkel Flow annotation workspace) can cumulatively enhance efficiency, but they won’t achieve a 10x improvement. A human with domain expertise and data access still needs to review each example individually, leaving the fundamental bottleneck largely unchanged. The labeling process remains opaque and difficult to reproduce.
Manual labeling requires humans to label examples one-by-one, posing a significant scalability challenge for auto data labeling.
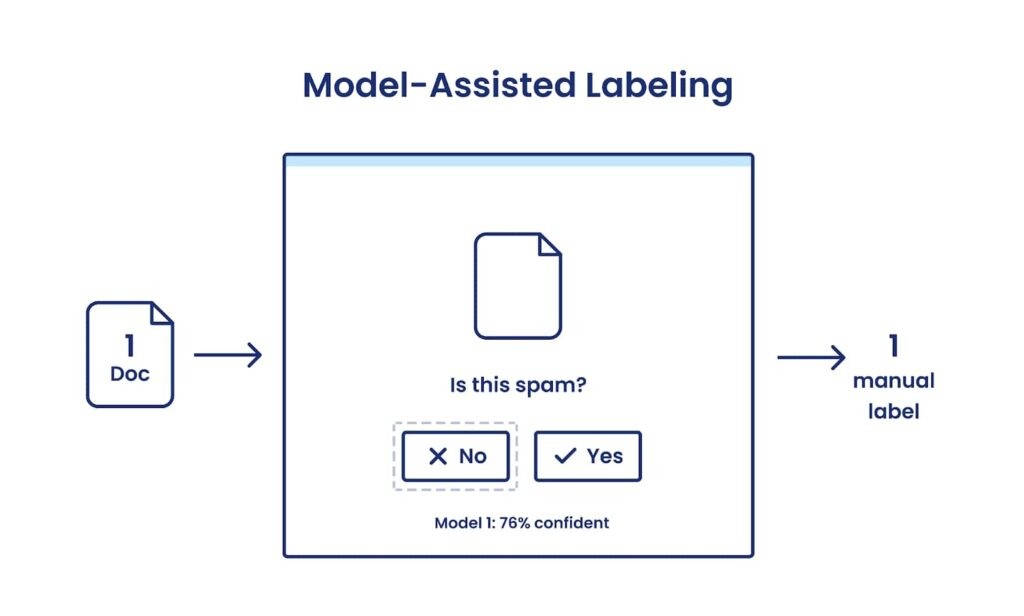
Model-Assisted Labeling: Incremental Efficiency
Model-assisted labeling, also known as “pre-labeling,” involves using an existing model (either a current model or one from a related task) to suggest initial labels for data points. Human labelers then manually approve or reject these suggestions.
This approach can be viewed as an enhanced UI for manual labeling. For tasks where individual label creation is time-consuming or requires numerous interactions (e.g., image segmentation), model-assisted labeling can save time by reducing the number of manual clicks. However, the fundamental process remains manual: a human still views and verifies each example, creating labels one at a time without associated functions for adaptability or governance. This represents another marginal improvement to manual labeling 19.
Crucially, even with human verification, using model-generated suggestions introduces the risk of biasing labelers. It can inadvertently reinforce existing model errors and biases. An MIT study 22 published at CHI 2021, a leading conference in human-computer interaction [21](#footnotes], demonstrated this phenomenon:
“…when presented with fully pre-populated suggestions, these expert users exhibit less agency: accepting improper mentions, and taking less initiative in creating additional annotations.”
This implies that this manual labeling enhancement might, in fact, be counterproductive, potentially decreasing model quality for relatively minor gains in efficiency.
Active Learning: Smart Data Point Selection
Active learning, a well-established machine learning technique with decades of research and application [10](#footnotes], aims to improve manual labeling efficiency by strategically ordering the examples to be labeled. The goal is to minimize the total number of labeled examples required. For instance, given constraints on time or budget, it might be preferable to label data points that are dissimilar to each other (and thus likely to provide new information) or those about which the model is least confident (and therefore likely to impact its decision boundaries).
In practice, reordering data points via active learning can enhance manual labeling efficiency in certain applications, especially early in a project when the model has learned relatively little. However, as the model learns, identifying the most valuable points to label becomes almost as complex as the original modeling problem itself, leading to diminishing returns over random sampling. Intuitively, if you perfectly knew the decision boundary between classes, you wouldn’t need to train a classifier to determine it.
Finally, because traditional active learning operates at the level of individual labels collected one at a time without associated rationale, it shares the limitations of knowledge transfer, adaptability, and governance inherent in other manual labeling methods. Overall, active learning is a sensible and standard approach to improve manual labeling efficiency, but it does not represent a fundamental shift in auto data labeling.
Active learning algorithms attempt to select the most informative data point for the next manual label, still one at a time, for more efficient auto data label.
Programmatic Labeling: A Practical Revolution in Auto Data Labeling
Programmatic labeling, also known as “data programming” or the “Snorkel approach,” fundamentally changes the input from humans. Instead of individual labels, the primary input becomes labeling functions (LFs) that encapsulate labeling rationale. These LFs are then applied programmatically to massive unlabeled datasets and aggregated to automatically generate large training sets.
Consider building a spam classifier. You might have various resources at your disposal: spam word dictionaries, a spam classifier from another domain, or even existing crowdworker labels. You likely also have heuristics or “rules of thumb” that you or domain experts would use for manual labeling—formal greetings like “dear sir or madam,” high typo rates, or links to wire transfer services.
You can express these resources and heuristics as labeling functions and apply them at scale to vast amounts of unlabeled data programmatically. Crucially, once a labeling function is written, no further manual effort is required to label data, whether it’s thousands or millions of data points. The same applies to model updates. To address an error mode, you simply add a new labeling function, and the entire training set can be regenerated programmatically without individual data point review.
Labeling functions can vary in coverage, accuracy, and correlation, and they will inevitably disagree. However, the Snorkel team and other researchers have developed algorithms to automatically learn how to weight these diverse sources of supervision during aggregation, based on their learned accuracies and correlations. Early versions of these aggregation strategies (circa 2016-2019) have been published in peer-reviewed papers 11 12 13 14 15 16 17 18, and these, along with many others, are available in Snorkel Flow.
Programmatic labeling offers four key advantages for auto data labeling:
- Truly Automated Labeling Process: Programmatic labeling automates the entire labeling process, delivering orders-of-magnitude efficiency gains. This contrasts sharply with manual labeling, where automation offers only marginal improvements around the edges.
- Human-Driven Labeling Decisions: While the process is automated, the labeling decisions remain firmly under human control. Domain experts leverage their knowledge to determine which resources and heuristics to apply via labeling functions.
- Governable Label Creation: Programmatic labeling ensures governability. Every training label can be traced back to its contributing factors. If dataset bias is detected, its source can be directly identified and removed.
- Lifecycle Efficiency Gains: The efficiency of programmatic labeling increases over the model lifecycle. Adapting to inevitable changes in problem definition or data distribution is easy—relabeling involves updating or adding labeling functions, not manual relabeling. New unlabeled data can be readily labeled and added to the training set without additional manual effort.
Each labeling function suggests training labels for multiple unlabeled data points based on human expertise. A label model (Snorkel Flow includes optimized variants) aggregates these weak labels into a single training label per data point to create the training set. The ML model then learns to generalize beyond the data points directly labeled by functions.
Furthermore, programmatic labeling is fully compatible with manual labeling optimizations. Active learning can guide the selection of data points for writing new labeling functions. Existing models can provide predictions to inform the creation of LFs 8. Users can then develop labeling functions based on these insights, updating labels for many more data points simultaneously than in manual workflows.
For deeper insights into programmatic labeling, explore this blog post on How Snorkel Works, this article on the origins of the Snorkel project, and the Snorkel AI website for case studies and peer-reviewed research applying this approach to real-world challenges.
Snorkel Flow: Automating Auto Data Labeling and Beyond
Snorkel Flow is a data-centric platform built to maximize the end-to-end capabilities of programmatic labeling for AI application development. Snorkel Flow makes modern auto data labeling accessible, guided, and performant, enabling users to:
- Explore data at various granularities (individual examples, search results, embedding clusters, etc.).
- Create no-code Labeling Functions (LFs) using GUI templates or custom code LFs in an integrated notebook environment.
- Auto-generate LFs from small labeled data samples.
- Use programmatic active learning to guide LF creation for unlabeled or low-confidence data clusters.
- Receive prescriptive feedback and recommendations for improving LFs.
- Execute LFs at scale to auto-generate weak labels on massive datasets.
- Auto-apply best-in-class label aggregation strategies, intelligently selected based on dataset properties.
- Train industry-standard models out-of-the-box or integrate custom models via Python SDK with one-click platform training.
- Perform AutoML searches for hyperparameter optimization and advanced training configurations.
- Conduct guided, iterative error analysis across models and data to enhance performance.
- Deploy final models as part of broader applications using preferred production serving infrastructure.
- Adapt to new requirements or data shifts by easily adjusting LFs and regenerating training sets in minutes.
While Snorkel Flow doesn’t mandate hand-labeled data, many teams find labeling a small ground truth subset valuable for evaluation and error analysis. Snorkel Flow provides a manual labeling workspace incorporating the optimization tools discussed earlier—keyboard shortcuts, active learning, and model-assisted labeling—along with project dashboards, annotator roles, review workflows, and user comments. Furthermore, Snorkel Flow supports advanced machine learning techniques compatible with programmatic labeling. These include:
- Semi-supervised learning: Leveraging labeling functions and aggregation strategies that incorporate both labeled and unlabeled data.
- Transfer learning: Fine-tuning pre-trained foundation models from industry-standard model zoos available within the platform.
- Few-shot and zero-shot learning: Creating LFs from contextual models that may not be perfect out-of-the-box but offer valuable signal.
Developing AI solutions should be a collaborative partnership between humans and machines. Humans provide intelligence, and machines automate the scalable capture and encoding of that intelligence into models. Programmatic labeling and the capabilities of Snorkel Flow make this ideal partnership a reality. To learn more about how automated data labeling can revolutionize your AI development, request a demo or visit our platform. Subscribe for updates or follow us on Twitter, LinkedIn, Facebook, YouTube, or Instagram.
Footnotes
- “Data preparation and [data] engineering tasks represent over 80% of the time consumed in most AI and Machine Learning projects.” Data Preparation & Labeling for AI 2020, Cognilytica.
- This topic is particularly of interest to those who subscribe to a data-centric view of AI development. https://github.com/HazyResearch/data-centric-ai.
- “June 2019 Workshop”. 2022. Snorkel.Org. https://www.snorkel.org/blog/june-workshop.
- Snorkel AI collaborates with Google, Intel, Stanford Medicine, DARPA, and customers such as Chubb, BNY Mellon, several Fortune 500 organizations, and government agencies
- “Technology”. 2022. Snorkel AI. https://snorkel.ai/technology/#research.
- “Twenty Questions – Wikipedia”. 2022. En.Wikipedia.Org. https://en.wikipedia.org/wiki/Twenty_questions.
- “Case Studies”. 2022. Snorkel AI. https://snorkel.ai/case-studies/.
- Gershgorn, Dave. 2017. “The Data That Transformed AI Research—And Possibly The World”. Quartz. https://qz.com/1034972/the-data-that-changed-the-direction-of-ai-research-and-possibly-the-world/.
- Bach, Stephen H., Daniel Rodriguez, Yintao Liu, Chong Luo, Haidong Shao, Cassandra Xia, and Souvik Sen et al. 2018. “Snorkel Drybell: A Case Study In Deploying Weak Supervision At Industrial Scale”. Arxiv.Org. https://arxiv.org/abs/1812.00417.
- Burr Settles’ technical report first published in 1995 and updated in 2009 is one of the most cited surveys of the technique. 2022. Minds.Wisconsin.Edu. https://minds.wisconsin.edu/bitstream/handle/1793/60660/TR1648.pdf
- Ratner, Alexander J., Christopher M. De Sa, Sen Wu, Daniel Selsam, and Christopher Ré. 2016. “Data Programming: Creating Large Training Sets, Quickly”. Advances In Neural Information Processing Systems 29. https://proceedings.neurips.cc/paper/2016/hash/6709e8d64a5f47269ed5cea9f625f7ab-Abstract.html.
- Ratner, Alexander, Stephen H. Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Ré. 2017. “Snorkel”. Proceedings Of The VLDB Endowment 11 (3): 269-282. doi:10.14778/3157794.3157797.
- Stephen H. Bach, Christopher Ré. 2017. “Learning The Structure Of Generative Models Without Labeled Data”. Proceedings Of Machine Learning Research 70: 273. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6417840/.
- Ratner, A., Hancock, B., Dunnmon, J., Sala, F., Pandey, S., & Ré, C. (2019). Training Complex Models with Multi-Task Weak Supervision. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), 4763-4771. https://doi.org/10.1609/aaai.v33i01.33014763.
- Varma, Paroma, Frederic Sala, Ann He, Alexander Ratner, and Christopher Ré. 2019. “Learning Dependency Structures For Weak Supervision Models”. Arxiv.Org. https://arxiv.org/abs/1903.05844.
- Varma, Paroma, Frederic Sala, Shiori Sagawa, Jason Fries, Daniel Fu, Saelig Khattar, and Ashwini Ramamoorthy et al. 2019. “Multi-Resolution Weak Supervision For Sequential Data”. Advances In Neural Information Processing Systems 32. https://proceedings.neurips.cc/paper/2019/hash/93db85ed909c13838ff95ccfa94cebd9-Abstract.html.
- Fu, Daniel Y., Mayee F. Chen, Frederic Sala, Sarah M. Hooper, Kayvon Fatahalian, and Christopher Ré. 2020. “Fast And Three-Rious: Speeding Up Weak Supervision With Triplet Methods”. Arxiv.Org. https://arxiv.org/abs/2002.11955.
- Chen, Mayee F., Daniel Y. Fu, Frederic Sala, Sen Wu, Ravi Teja Mullapudi, Fait Poms, Kayvon Fatahalian, and Christopher Ré. 2020. “Train And You’ll Miss It: Interactive Model Iteration With Weak Supervision And Pre-Trained Embeddings”. Arxiv.Org. https://arxiv.org/abs/2006.15168.
- Some techniques in the semi-supervised learning family (see https://link.springer.com/article/10.1007/s10994-019-05855-6 for a nice summary) take model-assisted labeling one step further and actually do apply the label without human review. This is made feasible by making certain assumptions about the distribution of the data and/or limiting the amount of “automatic” labeling that is allowed to occur in an attempt to limit semantic drift. However, these techniques also suffer from a lack of governability and the inability to transfer domain knowledge in a more direct form to the model than individual labels.
- “Perpetual Motion – Wikipedia”. 2010. En.Wikipedia.Org. https://en.wikipedia.org/wiki/Perpetual_motion.
- Human computer interaction – google scholar metrics. (n.d.). Retrieved February 4, 2022, from https://scholar.google.es/citations?view_op=top_venues&hl=en&vq=eng_humancomputerinteraction.
- “Assessing The Impact Of Automated Suggestions On Decision Making: Domain Experts Mediate Model Errors But Take Less Initiative | Proceedings Of The 2021 CHI Conference On Human Factors In Computing Systems”. 2022. Dl.Acm.Org. https://dl.acm.org/doi/10.1145/3411764.3445522.